Sentiment Analysis
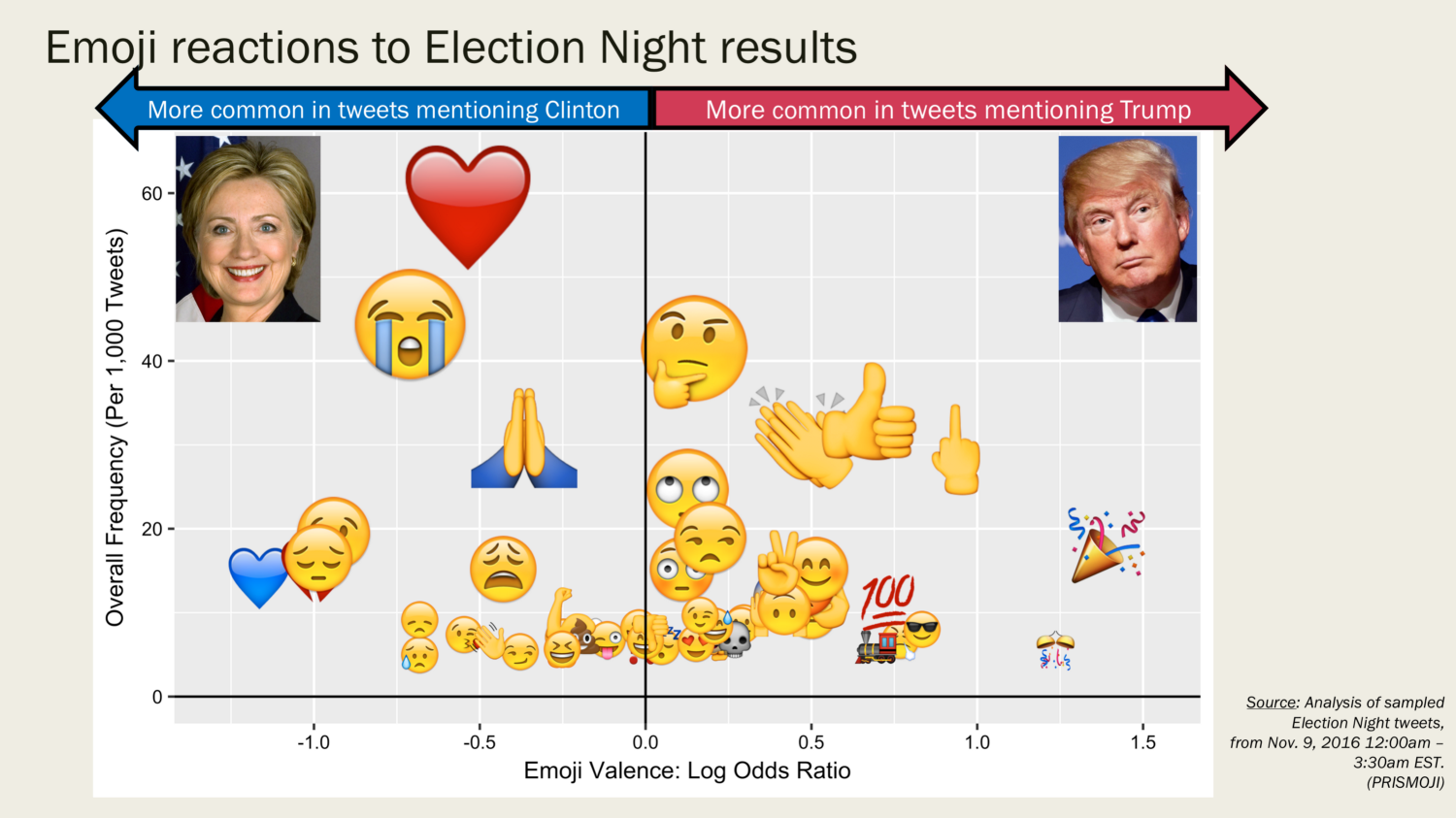
Sentiment analysis of emoji reactions to election night results (Source: Prismoji)
This year’s Wintersession Workshop picks up where last year’s left off in two ways. First, it’s rooted in the same time and place in history — down to the very room itself. Last year, we examined what historian Fred Turner has dubbed “the democratic surround”: the development of a multi-screen media environment stretching past an individual’s field of view and linear perception of time to enclose a greater collective and prototype a more interactive mode of viewing that, its originators argued, better represented the complexity of the modern age. Though we see traces of this multi-surface storytelling approach throughout art history, this new iteration of the “total environment” crystallized in a slideshow film by Charles and Ray Eames called “Glimpses of the USA,” created for the American National Exhibition in Moscow (the site of the famous “Kitchen Debate”) in 1959. Within a short time, the multi-screen approach would become institutionalized in the design of political spaces like the White House Situation Room (built 1961), in public spectacles like the World’s Fair in New York (1964), and in popular films like Dr Strangelove (1964).

IBM’s RAMAC 305 computer in a business setting in an undated photo (Source: ExtremeTech)
“Glimpses of the USA” was housed in a giant geodesic dome created by Buckminster Fuller, who’d been directed by one of the American National Exhibition’s organizers, George Nelson, to make it large enough to include a second installation positioned adjacent to the Eames’s enormous seven-channel display. That second exhibition, one of the most popular at the show, was the IBM RAMAC 305 computer, which was programmed to answer 4,000 questions about American life shown to Russian visitors on backlit panels — simple questions like “What is the price of American cigarettes?” or “What is jazz music?,” alongside more difficult political questions like “How many Negroes have been lynched in the U.S. since 1950?” After strolling by booths of GM cars and Kitchen Aid mixers, the Russians were invited to consume not goods but information itself.
Apart from the display of American technological progress and entertainment value of queuing with friends to learn trivia from far away and collect a souvenir printout with your question selection and answer, the RAMAC 305 mediated between the two tense nations at a critical time, providing a sense of objectivity to the Russian visitors, who would — or so hoped the US Information Agency, who authored the questions — ask the machine what they really wanted to know about the USA. Researcher Evangelos Kotsioris articulates this delicate circuit of American soft power on display in his paper, “Electronic ‘Ambassador’: The Diplomatic Missions of IBM’s RAMAC 305,”
[The] RAMAC 305 was still as much an output as an input system, collecting statistical data such as the total number of questions asked or the most popular questions requested in random order as they occurred. What was implied is that the processing of this large pool of data collected from Fair visitors could help classify and quantify the most common preoccupations of Soviets about American life and present them in a concise summary printout with mathematical, “unbiased” precision.
In other words, while it performed for its Russian visitors, the RAMAC 305 also performed an early example of sentiment analysis for the USIA.
So we come to the second way in which this year’s workshop picks up from the last. Then, we looked to perform an act of exposition — to explain, across multiple screens and surfaces, exactly how something worked. Now, our interest turns to how something makes us feel, and how we can come to understand, communicate, and categorize its emotional content. “An important part of our information-gathering behavior has always been to find out what other people think,” write Bo Pang and Lillian Lee of Cornell University, pioneers of the use of machine learning in sentiment analysis and authors of one of the most-cited papers on the subject. They observe,
With the growing availability and popularity of opinion-rich resources such as online review sites and personal blogs, new opportunities and challenges arise as people now can, and do, actively use information technologies to seek out and understand the opinions of others.
The objectives of sentiment analysis are simple: first, determine if a given bit of content (usually text) is positive or negative, and also if it falls into any emotional categories like “happy” or “angry.” Then, label it accordingly. Some researchers have studied methods by which text can be labelled as fact or opinion, while others have tried to mine content for sentiment on certain features or aspects of a product. The market-driven footing of the research indicates how much sentiment analysis has been developed for a society utterly unlike Moscow of the late-1950s — a culture where free, democratic thought is encouraged and product choice is plentiful.
Lately, there’s been a focus on the use of Natural Language Processing (NLP) to “read” a text with machine learning and conduct sentiment analysis on it. Movie reviews were an early example of this in 2002 because the scores at the end of the reviews on sites like Rotten Tomatoes helped to calibrate the NLP algorithms to better accuracy. NLP, interestingly enough, got its start a decade before the American Exhibition, first with the publication of Turing’s famous test for intelligent behavior in machines in 1950, and more practically with the demonstration of an automated Russian-to-English translation engine by researchers from Georgetown and IBM. According to an IBM press release from January 8, 1954,
A girl who didn’t understand a word of the language of the Soviets punched out the Russian messages on IBM cards. The “brain” dashed off its English translations on an automatic printer at the breakneck speed of two and a half lines per second.
“Mi pyeryedayem mislyi posryedstvom ryechyi,” the girl punched. And the 701 responded: “We transmit thoughts by means of speech.”
NLP has continued to evolve. Today, it allows us to dictate to our watches and determine the authorship of texts that may have been written by Shakespeare. Its growth, and the growth of machine learning more generally, has tracked closely with the expansion of data processing and storage power.
The other, more time-honored method for conducting sentiment analysis, though, is to make the output more machine-friendly by design. Polls, surveys, and elections aim to let our opinions be heard by making our voices more countable. Statisticians, marketers, and political scientists have known “sentiment analysis” by many other names in the course of their work. And the utter failure of these models to predict, reflect, or even clearly communicate the results of the 2016 US Presidential Election make our class’s focus and output, to my mind, all the more urgent. “Tonight data died,” Mike Murphy, a Republican strategist, told the New York Times on Election Night, having himself predicted a Clinton win earlier in the week. The OED announced the following week that its 2016 word of the year was “post-truth.”

Face with Tears of Joy emoji across multiple platforms (Source: Bustle)
A year earlier, the OED selected an emoji — “Face with Tears of Joy” — as its word of the year. The OED editors write,
😂 was chosen because it was the most used emoji globally in 2015. SwiftKey identified that 😂 made up 20% of all the emojis used in the UK in 2015, and 17% of those in the US: a sharp rise from 4% and 9% respectively in 2014. The word emoji has seen a similar surge: although it has been found in English since 1997, usage more than tripled in 2015 over the previous year.
By May 2015, half of the comments on Instagram used emoji, according to their engineering team, a remarkable figure. Facebook, which owns Instagram, launched more nuanced emoji-like Reactions (instead of only Likes), a few months later. Though they’d been around for over a decade — a simple set of 172 12×12 pixel emoji was drawn by Shigetaka Kurita in 1998-99 for Japanese cell manufacturer NTT DoCoMo to improve their messaging platform — their rise can be traced to Apple’s inclusion of an emoji keyboard in iOS in October 2011. A month later, Instagram found 10% of its comments included an emoji, and the trend line continued sharply upward from there. Aside from being fun and eye-catching, the little “picture characters” made human emotion much more machine-readable.
A surprising number of conversations around emoji quote from Ludwig Wittgenstein’s Tractatus Logico-Philosophicus: “The limits of my language mean the limits of my world.” The implication generally is that emoji form an “expansion pack” for the user’s limited native language, though that might not be exactly what he meant. (Philosophers do think Wittgenstein might’ve liked emoji, though — his concept of the “language game” was distinctly emoji-like.) What the quote captures, though, is the inherent incompleteness of all universal systems, and in recent years proposals to the Unicode Consortium, emoji’s governing body, to expand representation have taken on a distinctly more political dimension. Emoji’s implementation of flags using two alphabetic regional indicator symbols (U and S for the US) allow it to sidestep the formal recognition of nation-states and their changing flags and political regimes and leave that to the platforms like iOS and Android. It has also forbidden brands altogether, for similar reasons — although that hasn’t stopped brands from building marketing efforts around them, and players (like Twitter) looking to serve brands via emoji-like stickers. Emoji now support skin tones based on the Fitzpatrick Skin Type Classification Scale used by dermatologists, and, increasingly, gender diversity. Design features like zero-width joiners allow multiple emoji to be linked into new combinations eligible for recognition. A woman and the Staff of Aesculapius link together to form a female health worker. Families can be assembled in every combination of boys and girls, dads and moms. Because the Unicode Consortium only provides a verbal description of the emoji character, platforms like Android, iOS, and Windows can own, evolve, and maintain the emoji artwork they release, but the precise mechanics of copyright on emoji remains an evolving legal question. Even representation itself, as with all cartoons, remains a question — is it better for emoji to have the vivid look of a contemporary animated film, or the reductive line-work of an classic comic strip? The decision to represent the pistol emoji as a squirt gun means that when iOS user thinks he’s sending a playful message to Windows user, she may in fact be getting a very different image. Even the choice of guns is telling: most use a classic revolver, with LG and emojidex opting for something closer to a Glock.
{kind=link}
Anyway, enough preamble for me already. Let’s get on with the workshop. 😬
Assignment
Select one of the following projects to focus on for the duration of the workshop:
- Visualize either an existing or an original sentiment analysis study on an aspect of your thesis. (If doing your own, there are numerous online tools that can help.)
- Develop a proposal to modify the existing emoji set. You may wish to propose new functionality, add or subtract glyphs, or something else. Follow the Unicode Consortium guidelines and conduct necessary research for your proposal. I have included samples of recent proposals in the links below.
To receive a grade, you must provide digital documentation of your project to me via the email address above by the last Friday of Wintersession, 02/03. Please link to large files (>8MB) rather than attaching them directly. I expect you will revisit, revise, and extend your project for our final critique in late February or early March (date TBD). You may work alone or in groups. As you work, be sure to save all sketches, correspondence, and drafts — be meticulous about your process.
Required for discussion:
- a16z Podcast: The Meaning of Emoji
- P. Kralj Novak, J. Smailovic, B. Sluban, I. Mozetic: Sentiment of Emojis, Emoji Sentiment Ranking, and Emoji Sentiment Map
In addition, select from the links above or below an article of interest and come prepared to give a brief, 5 minute summary to the group on your selection
Additional links and references
Emoji
- Anthony Leondis (director): The Emoji Movie (trailer)
- Tim Peters: Emoji, Comics, and the Novel of the Future
- Laur M. Jackson: E•MO•JIS
- Robinson Meyer: Emoji Are Designed to Be More Permanent Than Countries, and Canada Loves the Poop Emoji
- Tom McCormack: Emoticon, Emoji, Text Pt 1,Pt 2
- Miller, Thebault-Spieker, Chung, Johnson, Terveen, Hecht: “Blissfully happy” or “ready to fight”: Varying Interpretations of Emoji
- Adam Sternbergh: Smile, You’re Speaking Emoji
- Hamdan Azhar: An introduction to emoji data science
- Emojipedia
- Emojicon 2016
- Rachel Been and Augustin Fonts: Taking the Equality Conversation to Emoji
- Paul Galloway: The Original Emoji Set Has Been Added to The Museum of Modern Art’s Collection
- Colin Ford: Emoji: Fonts, Technically Emoji: A Lovely History Emoji: Looking Good! Emoji: Setting the Tables Making Emoji with Always With Honor
Sentiment analysis and visualization
- Dan Jurafsky & Chris Manning (Stanford NLP): What is Sentiment Analysis?
- Sam Petulla: Feelings, nothing more than feelings: The measured rise of sentiment analysis in journalism
- Sarah Kessler: The Problem with Sentiment Analysis
- Jonathan Harris: The Web’s Secret Stories
- Edward Tufte: The Visual Display of Quantitative Information (Ch. 1)
Otto Neurath
- Otto Neurath: International Picture Language
- Frank Hartmann: Humanization of Knowledge Through the Eye
- Nader Vossoughian: Mapping the Modern City: Otto Neurath, the International Congress of Modern Architecture (CIAM), and the Politics of Information Design
Sample Unicode Technical Committee proposals
- Havas London: Condom Emoji Submission (v2)
- Been, Bleuel, Fonts, Davis: Expanding Emoji Professions: Reducing Gender Inequality
- Lee, Lu, Lau, Mujumdar, Emojination: Dumpling Emoji Submission
- Loomis, Winstein, Lee: Coded Hashes of Arbitrary Images
- Various authors: Unicode Technical Committee Document Registry